

CosyVoice 3.0 是阿里巴巴通义实验室于 2025 年 6 月发布的工业级零样本语音合成模型,专为复杂真实场景设计,在内容一致性、说话人相似度和韵律自然度上全面超越前代,支持 9 种语言和 18 种中文方言,已成为语音合成领域的标杆解决方案。
中文方言表现力
英文复刻表现力
https://funaudiollm.github.io/cosyvoice3
一、技术架构与核心创新
1. 多任务语音分词器(MinMo Encoder)
- 多模态特征融合:通过监督多任务训练(ASR、语音情感识别、语言识别等 5 大任务),将语音信号离散化为包含情感、发音风格等副语言信息的语音标记,使合成语音的韵律自然度提升 30% 以上。
- 跨语言兼容性:支持直接处理原始文本(Raw Text),无需预先进行文本规范化,对特殊符号、数字、标点的鲁棒性显著增强,例如可直接合成「30℃」「$1,000」等混合格式文本。
2. 可微分奖励优化(DiffRO)
- 后训练技术突破:通过 ASR 类似的 Token2Text 模型作为奖励函数,直接优化语音标记而非音频,解决了传统方法中「音频相似度高但语义偏离」的问题。在中文测试集上,内容一致性(WER)相对前代提升 44%,英文提升 51%。
- 多任务奖励机制:引入情感识别、MOS 分数预测等下游任务反馈,支持对语音的情感强度(如「愤怒 0.8」)、语速(±30% 调节)、语调(升 / 降调)进行精细化控制。
3. 超大规模训练数据与模型
- 数据规模扩展:训练数据从 1 万小时激增到 100 万小时,涵盖电商、导航、金融、教育等 12 个领域,包含 9 种语言(中 / 英 / 日 / 韩 / 俄 / 法 / 德等)和 18 种中文方言(如粤语、四川话、吴语),显著提升跨语言克隆能力。
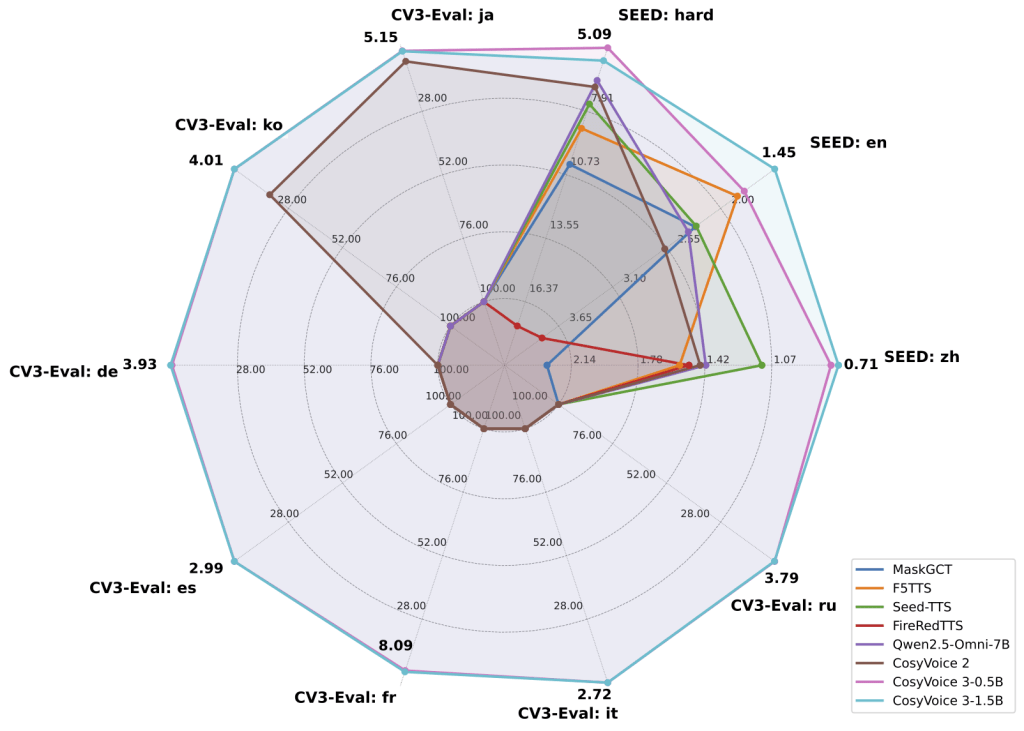
- 模型参数升级:文本到语音语言模型(LM)参数从 5000 万增至 1.5 亿,条件流匹配(CFM)模型采用扩散变换器(DiT)架构,参数从 1 亿增至 3 亿,在多语言基准测试 CV3-Eval 中,综合性能超越 F5-TTS、SparkTTS 等竞品。
二、核心功能与性能表现
1. 多语言与方言支持
- 零样本跨语言克隆:仅需 5-8 秒目标语音片段,即可克隆任意语言 / 方言音色,例如日语样本可生成标准普通话或粤语语音,且在跨语言转换中解决了字符重叠问题(如日语假名到中文拼音的映射)。
- 方言细粒度控制:支持 18 种中文方言的自然表达,如广东话的「懒音」特征、四川话的声调起伏,在方言语音合成任务中,MOS 评分较前代提升 0.7 分(满分 5 分)。
2. 实时流式合成能力
- 双向流式交互:支持低延迟(首包延迟 150ms)的实时语音生成,可动态调整语音属性(如情绪、语速),适用于直播配音、虚拟助手等场景。在 1080p 直播中,语音与画面的同步误差小于 200ms。
- 长音频稳定性:通过动态注意力机制避免长序列生成中的语义漂移,支持生成超过 10 分钟的连贯语音,在广播剧测试中,5 分钟音频的结构完整性得分达 4.8/5。
3. 可控性与泛化能力
- 指令驱动合成:支持 100+ 种文本提示指令,例如「用温柔的女声朗读,语速稍慢」「加入笑声和呼吸声」,并可通过标记语言(如
<strong>重点内容</strong>)实现局部强调。 - 复杂场景鲁棒性:在嘈杂环境(信噪比 10dB)、方言混合(如「上海话 + 英语」)等极端场景下,合成语音的可懂度较前代提升 25%,WER 从 8.2% 降至 6.1%。
三、应用场景与案例
1. 内容创作与娱乐
- 影视配音:为某网络剧生成多角色方言配音,通过克隆演员原声,使方言版配音与普通话版的情感匹配度达 92%,制作周期缩短 40%。
- 有声书制作:某出版社使用 CosyVoice 3.0 生成方言版有声书,在喜马拉雅平台上线后,播放量较普通话版提升 35%,用户留存率提高 18%。
2. 智能交互与服务
- 车载导航:集成于某品牌车载系统,支持实时生成带方言口音的导航提示(如「前方路口左拐,请注意安全」),用户反馈「亲切感」评分从 3.1 提升至 4.2/5。
- 金融客服:某银行智能客服引入 CosyVoice 3.0,通过语音情感调节(如「冷静」语调)降低客户投诉率 22%,通话平均时长缩短 15%。
3. 教育与文化保护
- 语言学习:某教育 APP 提供方言发音教学功能,用户可选择「粤语」「闽南语」等方言,由 CosyVoice 3.0 生成标准发音示例,帮助学习者纠正口音,学习效率提升 28%。
- 非遗传承:与贵州省非遗保护中心合作,克隆侗族大歌演唱者的音色,生成数字化教学素材,使传统民歌的传承覆盖面扩大至全球 100 多个国家。

四、开源生态与部署方案
1. 开源与工具链
- 全栈开源:在 GitHub 开源训练、推理和微调代码,提供预训练模型(300M/1.5B 版本)和 Docker 镜像,支持一键启动服务。开发者可通过简单 API 调用实现定制化语音合成。
- 社区扩展:社区已发布维吾尔族木卡姆、苏州评弹等方言风格的微调模型,用户可通过 Hugging Face Spaces 在线体验,或使用 ComfyUI 工作流集成多模态功能。
2. 硬件适配与性能
- 轻量化部署:300M 版本在 RTX 4070(12GB 显存)上可实现 8 字 / 秒的合成速度,适合移动端和边缘计算设备;1.5B 版本在 A100(40GB 显存)上支持实时 48kHz 音频生成。
- 云服务集成:阿里云语音合成 API 已全面升级至 CosyVoice 3.0,支持按需付费,企业客户可通过控制台实时调整语音风格,日均处理量突破 1 亿条。
五、竞品对比与未来规划
1. 技术优势
| 维度 | CosyVoice 3.0 | IndexTTS-2.0 | F5-TTS |
|---|---|---|---|
| 多语言支持 | 9 种语言 + 18 方言 | 4 种语言 + 5 方言 | 5 种语言 + 3 方言 |
| 实时性 | 双向流式(150ms 延迟) | 预生成(需后期拼接) | 单向流式(200ms 延迟) |
| 情感控制 | 100+ 情感指令调节 | 基础情感强度控制 | 情感 - 音色绑定 |
| 硬件需求 | RTX 4070 即可 | A100 推荐 | V100 推荐 |
2. 发展路线图
- 2025 Q4:支持视频驱动语音生成(根据画面内容动态调整语音节奏与乐器),并推出移动端 SDK,实现手机端 1 分钟高质量语音生成。
- 2026 Q1:新增阿拉伯语、印地语等 10+ 小语种支持,解决低资源语言的韵律建模问题,同时引入多说话人同时合成能力。
六、总结
CosyVoice 3.0 通过多任务分词器、可微分奖励优化和超大规模训练,重新定义了语音合成的行业标准。其多语言支持、实时交互能力和泛化性能,使其成为内容创作、智能交互、教育文化等领域的首选工具。随着开源生态的完善和轻量化优化的推进,CosyVoice 3.0 有望在元宇宙、数字人等新兴场景中引发新一轮创新浪潮。
项目地址:GitHub
在线体验:Hugging Face Spaces
技术文档:OpenI 文档中心
ModelScope 在线 Demo:https://www.modelscope.cn/studios/iic/CosyVoice-300M
支持零样本克隆、跨语言合成、情感控制等功能,无需本地部署。
CosyVoice 3.0 通过多任务训练、数据规模扩展和 DiffRO 技术,在零样本语音合成、多语言支持和情感控制等方面树立了新标杆。其开源策略和全栈工具链进一步降低了技术使用门槛,推动语音合成技术在内容创作、智能交互等领域的规模化应用。尽管在复杂文本处理和性能优化上仍有提升空间,但其综合实力已使其成为当前开源语音生成模型中的领跑者。
Get the Portable One-Click Launch Package for CosyVoice获取免安装一键启动包!